How do I find the next Lionel Messi
Using statistical method to help you find similar playing style soccer players
2018 World Cup is coming
2018 FIFA World Cup is right around the corner, It might be missing some big nations, like Italy, Netherlands, USA or China (Highest populations). But that’s what makes this tournament the best in sports. If you check out the Google Trend and type in keyword Soccer, you could easily tell a bump in searches in every four years. Brazil are looking to bounce back from a travesty 7:1 in 2014, while Spain and France are hoping to dethrone defending champions Germany. Can Korean, Japan or Iran make a splash for Asian ? What would be the destiny of England ? There are so many doubts to be answered in this summer, In the coming weeks the world will be paying close attention to these teams and look forward to seeing the final Winner in July !
By now 6/4/2018, all nations have already submit their final 23-man World Cup squad, there are some under-the-radar names that in the list. For example, Renato Augusto, the Brazilian midfielder who currently played in Chinese soccer club Beijing GuoAn, might not be a household name, but certainly he is indispensable to the team. So Fans are wondering can we have a preview of this player’s playing style? How does he compare with other brazilian midfielder like Paulinho ? and How do I find a similar player like him ?
Luckily, this is a way to answer these questions, I got this amazing FIFA 18 dataset from Kaggle competition https://www.kaggle.com/thec03u5/fifa-18-demo-player-dataset and it contains more than 40 attributes for each player and also their national, club and position information. I am going to use these attributes data to build out our soccer player recommender system, to help you learn more about Renato Augusto. (The script is written in Python)
# Import packages
import numpy as np
import pandas as pd
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
import sys
reload(sys)
sys.setdefaultencoding('utf8')
from scipy.stats import entropy
import operator
# Basic exploration on the dataSet
# Ignore some details
player = pd.read_csv("fifa-18-demo-player-dataset/CompleteDataset.csv")
player.columns
player = player.iloc[:, [1,2,4,6,7,8,10,11,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,63]]
player.shape
# There are 17981 player with 43 different attribute
player.dtypes
# The dataset contains some updated information on player's attribute value i.e. 85 + 2,
# so we need to complete the calculation
def update_score(score):
score = str(score)
if '+' in score:
old, updates = score.split("+")
new_score = int(old) + int(updates)
return str(min(new_score, 100))
elif '-' in score:
old, updates =score.split("-")
new_score = int(old) - int(updates)
return str(max(0, new_score))
else:
return score
# Only include numeric metrics
numeric_attributes = ['Overall','Potential','Acceleration','Aggression','Agility','Balance','Ball control','Composure','Crossing','Curve','Dribbling','Finishing','Free kick accuracy','GK diving',
'GK handling','GK kicking','GK positioning','GK reflexes','Heading accuracy','Interceptions','Jumping','Long passing','Long shots','Marking','Penalties','Positioning',
'Reactions','Short passing','Shot power','Sliding tackle','Sprint speed','Stamina','Standing tackle','Strength','Vision','Volleys']
for attr in numeric_attributes:
player[attr] = player[attr].apply(lambda x: update_score(x)).astype(int)
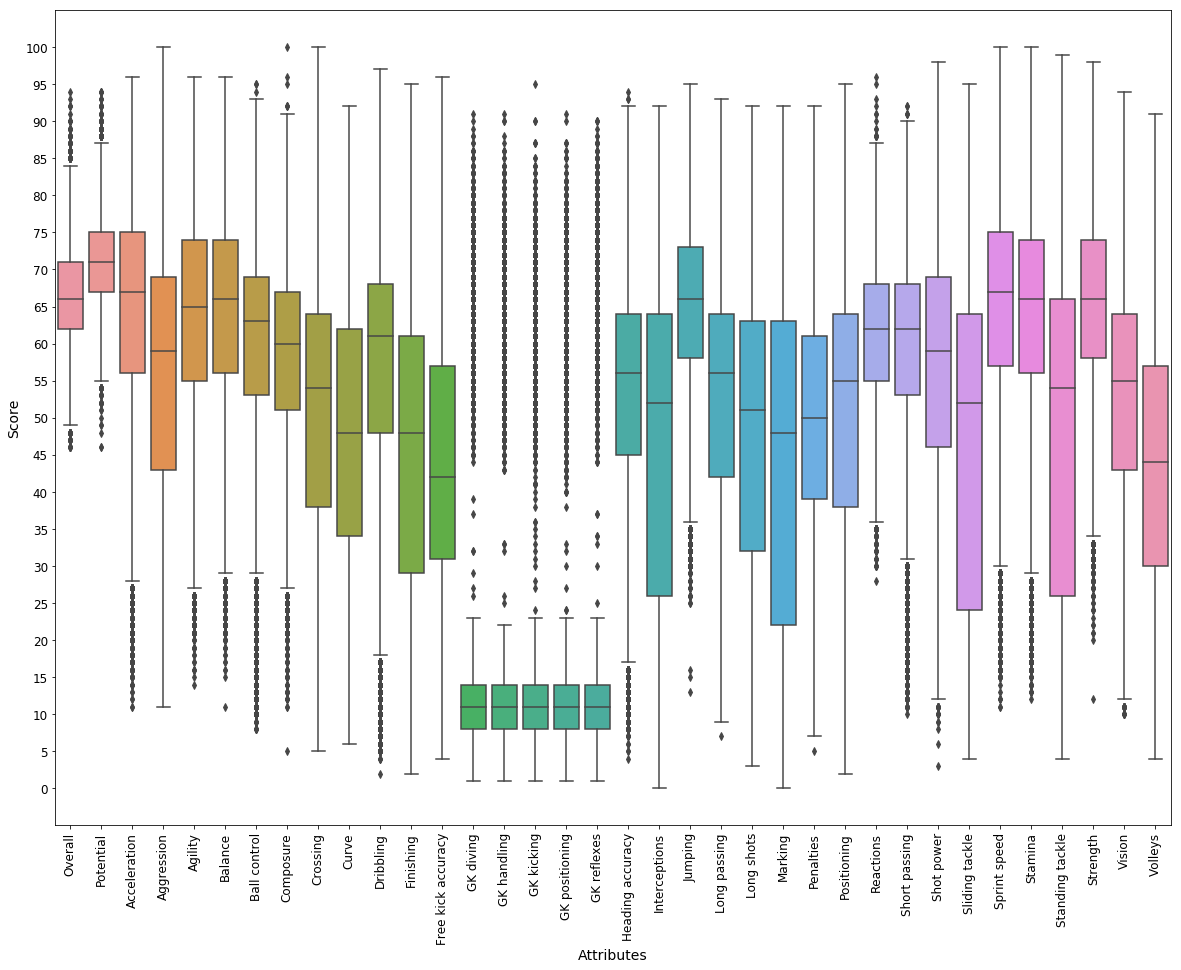
# Distribution of each attribute
player_attribute = player[numeric_attributes]
player_attribute.describe()
plt.subplots(figsize = (20, 15))
sns.boxplot(x = "variable", y = "value", data = pd.melt(player_attribute))
plt.xticks(rotation = 'vertical')
plt.yticks(np.arange(0, 101, 5))
plt.ylabel("Score")
plt.xlabel("Attributes")
# Correlation coefficients between these attributes
attribute_corr = player_attribute.corr()
plt.subplots(figsize = (25, 20))
sns.heatmap(attribute_corr, xticklabels = attribute_corr.columns,
yticklabels = attribute_corr.columns,
cmap = 'RdBu_r', annot = True)
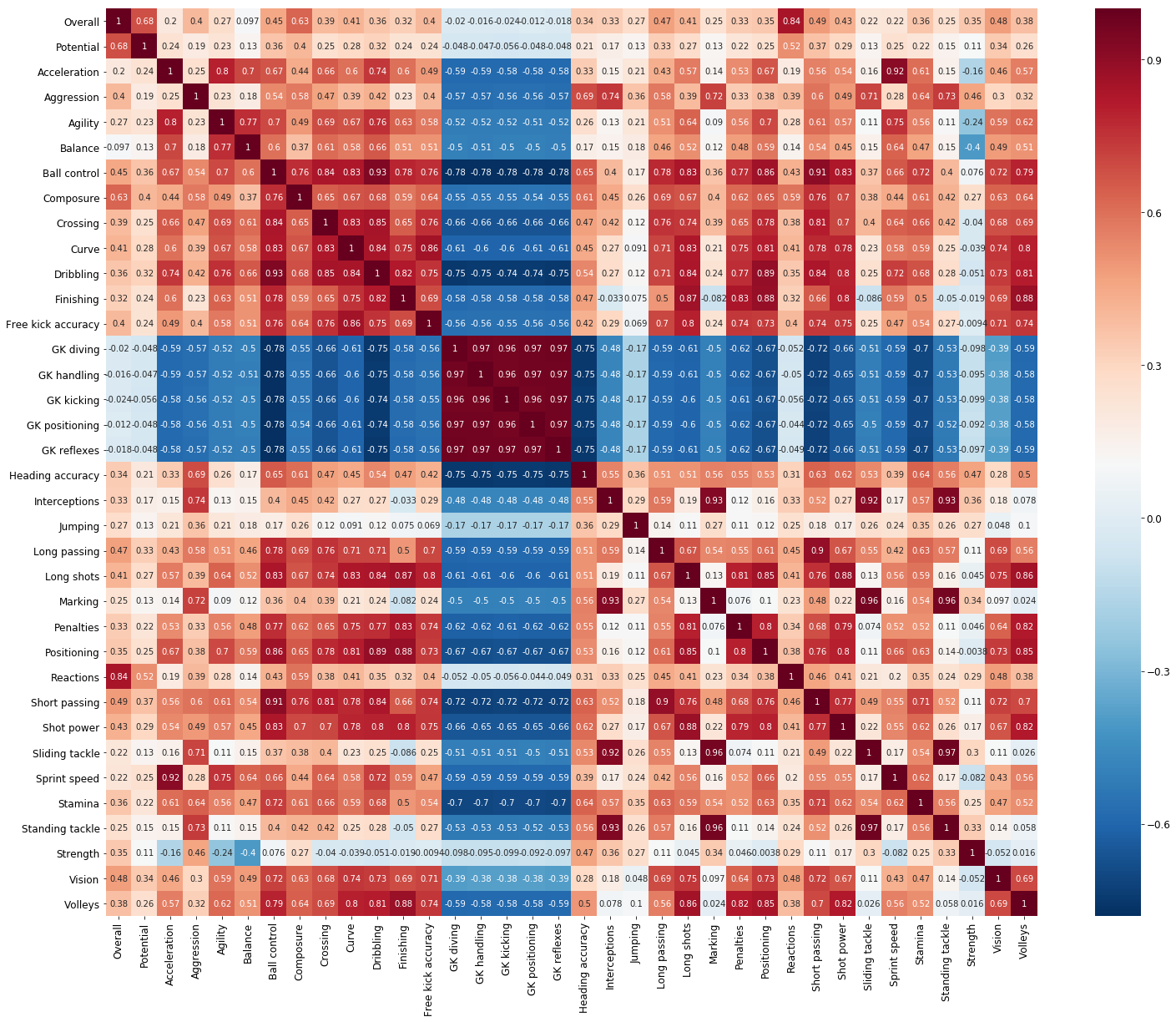
There are many interesting findings from the above plots, Defender’s key attributes (Interception, Marking, Sliding Tackle..) always have high variances, Reactions is highly correlated with one’s overall rating, Marking skills is related with Aggressions, and Jumping is kind like a independent attribute which is not correlated with any other attributes. Balance and Strength have negative correlation, which implies smaller sized players usually have higher balance as they have lower centres of gravity, and can often ride tackles and stay on their feet.
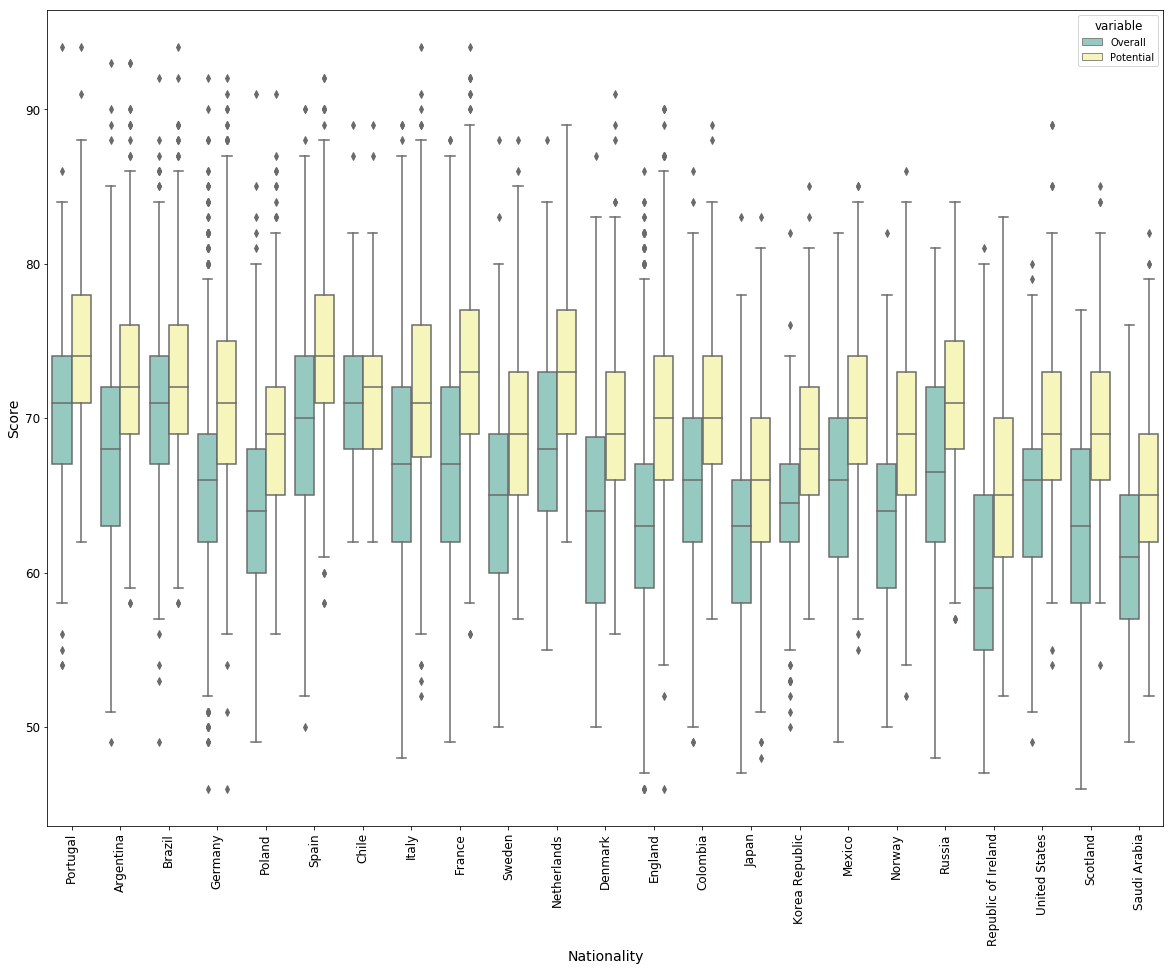
# Player's Overall Ratings by Countries
# I only include the nations that have more than 400 players in the dataset
# The subset samples contain 11 countries
player_by_nation = player.groupby(['Nationality'])['Name'].apply(lambda x : len(x)).reset_index()
great_soccer_nations = player_by_nation.loc[player_by_nation.Name >= 300,'Nationality'].values
player_subset = player[player.Nationality.isin(great_soccer_nations)].reset_index(drop = True)
plt.figure(figsize=(20, 15))
sns.boxplot(x = "Nationality", y = "value", hue = 'variable', data = pd.melt(player_subset[['Nationality','Overall','Potential']], id_vars = 'Nationality'), palette="Set3")
plt.xticks(rotation = 'vertical')
plt.xlabel("Nationality")
plt.ylabel("Score")
In order to find similar player, I used the Kullback-Leibler divergence (also called relative entropy), it’s a measure of how one probability distribution diverges from a second probability distribution. I normalize players’ attributes score to be probability distribution, then pick the target player we are interested to compare with other players distribution and sort the result from highest to lowest, finally return top K similar player with lowest kl-divergence score
player_name = 'Renato Augusto'
def returnSimilarPlayer(df, player_name, overall_difference = 5, results = 5):
similar_player = {}
overall_rating = df.loc[df.Name == player_name, 'Overall'].values[0]
attributes_rating = df.ix[df.Name == player_name, 3:].values[0]
for row in df.itertuples(name = None):
if abs(row[2] - overall_rating) <= overall_difference:
kl_distance = entropy(attributes_rating, np.array(row[4:]))
similar_player[(row[1], row[2])] = kl_distance
similar_player_cp = sorted(similar_player.items(), key = operator.itemgetter(1), reverse = False)
return similar_player_cp[1:results + 1]
print( returnSimilarPlayer(player_subcolumns, player_name) )
The similar player with Renato Augusto that returned from the methods are J. Veretout, V. Vada, Parejo, M. Brozovi and M. Pjanic.
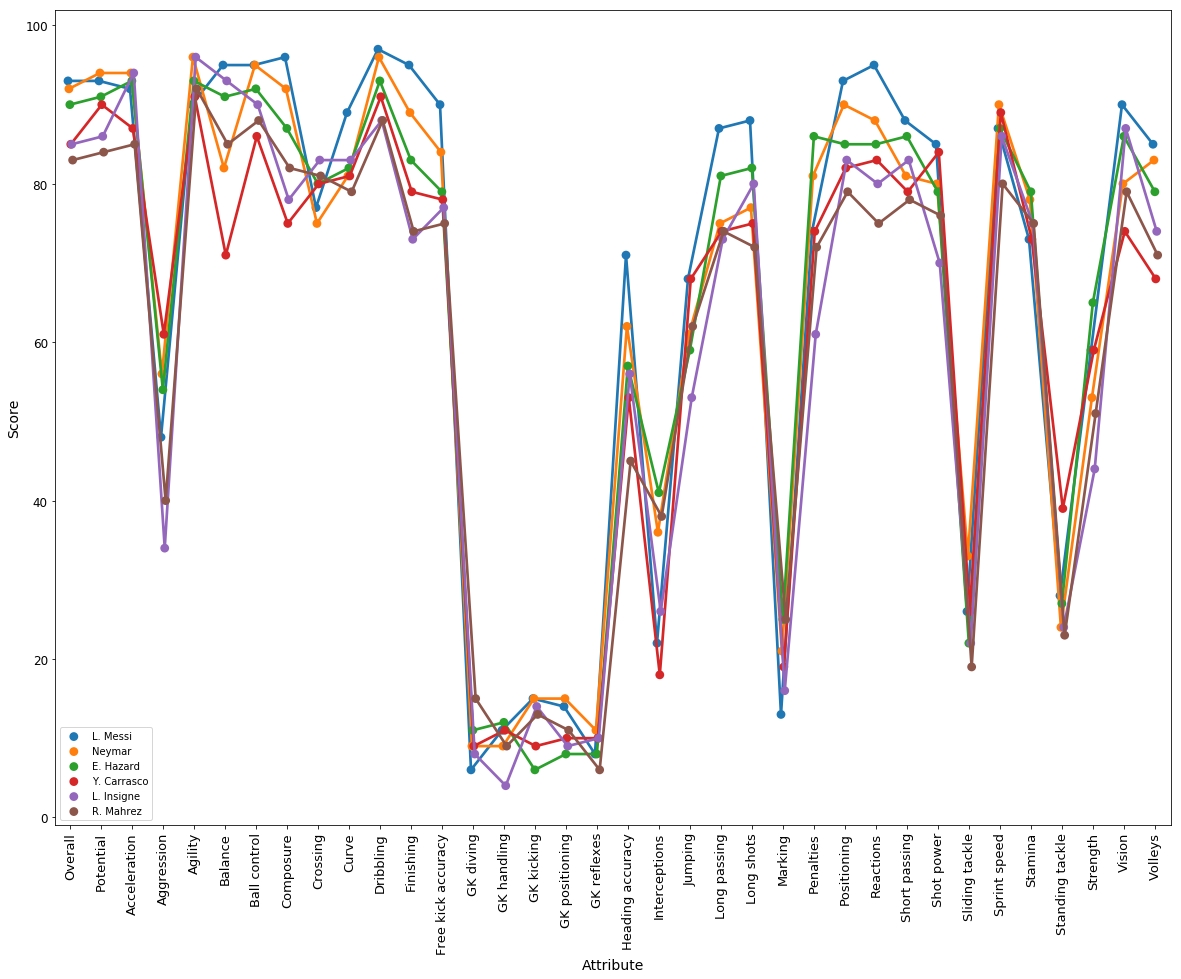
I also run the method again to see the similar player with Lionel Messi, the top 5 players are Neymar, L. Insigne, Y. Carrasco (playing in China now), E. Hazard and R. Mahrez
# Plot the attribute scores for these six players
best_player = player_attribute_long[player_attribute_long.Name.isin(['L. Messi', 'Neymar', 'L. Insigne','Y. Carrasco','E. Hazard','R. Mahrez'])].reset_index(drop = True)
plt.subplots(figsize = (20, 15))
sns.pointplot(x = "variable", y = "value", hue = "Name", data = best_player, dodge =True)
plt.xticks(rotation = 'vertical', fontsize = 13)
plt.xlabel("Attribute")
plt.ylabel("Normalized Score")
plt.legend()